
Data
AI Can't Agree on What Good Writing Is
We use three independent AI evaluators in the AgentPulse v2.2 benchmark: Claude Opus 4.6, Gemini 3.1 Pro,
AgentPulse benchmark results, model comparisons, and cost analysis backed by our own research data.
We use three independent AI evaluators in the AgentPulse v2.2 benchmark: Claude Opus 4.6, Gemini 3.1 Pro,

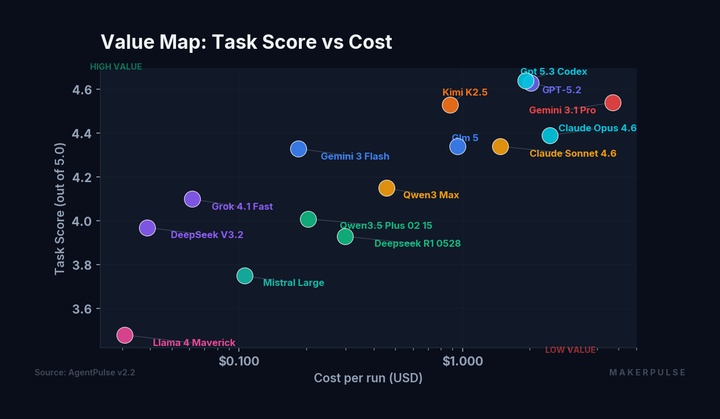
Llama 4 Maverick scores 3.48 on task quality in our AgentPulse v2.2 benchmark. Respectable. Then you ask it

MiniMax M2.5 scores 80.2% on SWE-bench Verified. Claude Opus 4.6 scores 80.8%. The difference is

The prose is good now. Really good. In our AgentPulse v2.2 benchmark, which tested 15 models across 28 prompts

There's been a reliable tradeoff in frontier AI models for months: you pick the one that handles tasks
Last updated: February 2026 | AgentPulse v2.2 | 15 models, 28 prompts, 1,260 evaluations We built AgentPulse because we needed

The hype around Chinese AI is everywhere right now. Kimi K2.5 generated more revenue in its first 20 days

When we ran 10 models through 7 creative writing prompts in the AgentPulse v2.2 benchmark, the scores moved in

The cost spread across capable frontier AI models is over 100x. Our latest AgentPulse benchmark run tested 10 models across

One-hundredth of a point. That's the task quality gap between Gemini 3 Flash Preview and Claude Sonnet