MCP Under the Hood: How the Model Context Protocol Actually Wires Agents to Everything
Ten thousand. That's how many active public MCP servers exist as of early 2026, according to Anthropic's December 2025 announcement. Unofficial registries count closer to seventeen thousand. A year ago, the Model Context Protocol was a quiet experiment from Anthropic. Today it's the wiring layer that connects Claude, ChatGPT, Gemini, VS Code, and Cursor to the outside world. In December 2025, Anthropic donated MCP to the Agentic AI Foundation under the Linux Foundation, with OpenAI and Block as co-founders. Every major LLM provider now treats MCP as standard infrastructure.
That's a lot of adoption for a protocol most practitioners still describe as "the thing that connects AI to tools." It does, but the how matters enormously. And the spec has some opinions that aren't obvious until you've actually read it.
Why You Should Care About a JSON-RPC Spec
The basic pitch is simple. Before MCP, every AI application that wanted to use external tools built its own integration. Claude had one way of calling a database. ChatGPT had another. If you wrote a tool integration for one, you rewrote it for the other. MCP standardizes that interface: build one server, and any MCP-compatible client can use it.
That pitch undersells what's actually going on. MCP isn't just a tool-calling protocol. It defines three distinct types of things a server can expose to an AI application: tools (executable functions), resources (read-only data), and prompts (templated interaction patterns). Most coverage treats these as interchangeable. They're not. The distinction between them is one of the more interesting design decisions in the spec, and it shapes how agents actually interact with external systems.
The timing matters, too. OpenAI rolled full MCP support into ChatGPT under Developer Mode, turning it into what VentureBeat called "a programmable automation hub." Google launched A2A (Agent-to-Agent) in April 2025 as an explicit complement to MCP, handling agent-to-agent communication while MCP handles the agent-to-tool layer. Microsoft ships MCP support in VS Code and Copilot. The convergence is real. If you're building anything that an LLM needs to interact with, MCP is the interface you're building against whether you planned on it or not.
Three Layers, Two Transports, One Very Stateful Handshake
MCP's architecture has three participants. A host is the AI application itself: Claude Desktop, Cursor, VS Code. The host creates one or more clients, each of which maintains a dedicated connection to a single server. A server is any program that exposes tools, resources, or prompts over the protocol. The host-to-client-to-server chain means a single AI application can connect to a filesystem server, a database server, and a Slack server simultaneously, each through its own client instance.
Under the hood, everything speaks JSON-RPC 2.0, the same wire format that the Language Server Protocol uses. That's not a coincidence. David Soria Parra, Anthropic's Member of Technical Staff who co-created MCP alongside Justin Spahr-Summers, has described how the design was "heavily inspired by how the language server protocol works." The team needed something line-based for standard I/O communication, and JSON-RPC fit. Soria Parra has been candid about the tradeoffs, saying he's "somewhat ambivalent" about this choice today, noting it has "some drawbacks" and that certain things "might be better in a more classic API-like way on the HTTP layer."
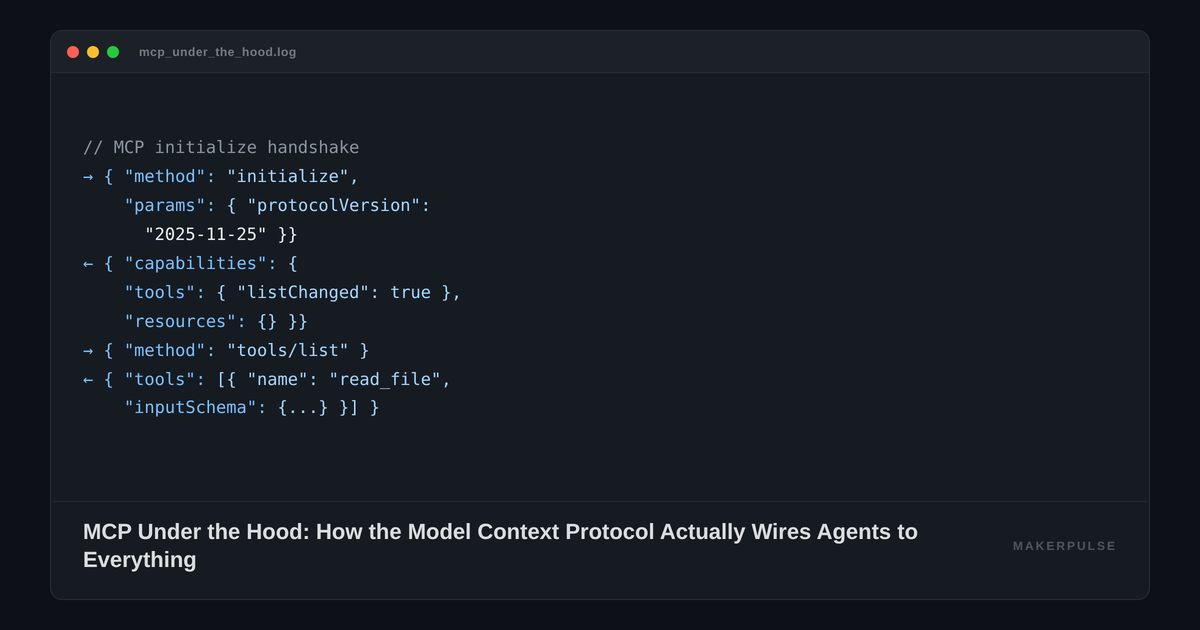
The protocol is stateful. Before any tool call happens, the client and server exchange an initialize handshake where they negotiate capabilities. The client says: "I support elicitation" (the ability to ask the user for input mid-operation). The server responds: "I support tools with dynamic list updates, and resources." This capability negotiation means neither side wastes time requesting features the other can't provide. After the handshake, the client sends a notifications/initialized message, and the connection is live.
Here's what that looks like on the wire:
// Client → Server
{
"jsonrpc": "2.0", "id": 1,
"method": "initialize",
"params": {
"protocolVersion": "2025-11-25",
"capabilities": { "elicitation": {} },
"clientInfo": { "name": "my-agent", "version": "1.0" }
}
}
// Server → Client
{
"jsonrpc": "2.0", "id": 1,
"result": {
"protocolVersion": "2025-11-25",
"capabilities": {
"tools": { "listChanged": true },
"resources": {}
},
"serverInfo": { "name": "filesystem-server", "version": "2.1" }
}
}
Two transport mechanisms carry these messages. Stdio transport pipes JSON-RPC over standard input and output between local processes. When Claude Desktop launches a filesystem server on your machine, it spawns a child process and communicates through stdin/stdout. Zero network overhead. No authentication needed because both processes run under the same user.
The second transport is Streamable HTTP, which replaced the original Server-Sent Events (SSE) transport in the March 2025 spec revision. The old approach used SSE for server-to-client streaming and a separate HTTP POST endpoint for client-to-server messages. Two connections, two sets of problems: SSE drops during long-running operations would lose responses, and the always-open connection created security blind spots where authentication only happened once. Streamable HTTP collapses this into a single endpoint handling bidirectional communication. It's the transport you use for remote servers, and it supports standard HTTP auth, including OAuth 2.1 as of the March 2025 spec (with further authorization improvements, including RFC 8707 Resource Indicators, added in June 2025).
When do you pick each? Stdio for local tools that run on the developer's machine (file systems, local databases, build tools). Streamable HTTP for anything remote (SaaS integrations, cloud APIs, shared team tools). If you're writing a Sentry integration or a GitHub server, you want Streamable HTTP so many clients can connect simultaneously.
Tools, Resources, and Prompts Are Not the Same Thing
This is the part of the spec that most tutorials gloss over. MCP defines three primitives, and they have different control models.
Tools are model-controlled. The LLM decides when to call them based on context. Each tool has a name, a description, and a JSON Schema defining its inputs. When you call tools/list, you get back an array of these definitions. The model reads them, understands what's available, and invokes tools/call when appropriate. Tools can write to databases, fire API calls, modify files. They're the dangerous primitive.
Resources are application-controlled. They provide read-only access to data: file contents, database schemas, API documentation. Each resource has a URI (file:///path/to/document.md) and a MIME type. The host application decides which resources to fetch and feed to the model as context. Resources support subscriptions, so a client can monitor changes. But the model doesn't invoke resources on its own; the application orchestrates that.
Prompts are user-controlled. They're reusable templates that structure interactions. Think slash commands: a user selects "Plan a vacation" or "Summarize this database," and the prompt provides structured arguments and a workflow pattern. The model doesn't autonomously trigger prompts. A human does.
This three-way split is a deliberate safety choice. If tools and resources were the same primitive, the model could autonomously decide to read your entire filesystem and then execute arbitrary functions. Separating them creates friction by design. The application gates what context the model sees (resources), and the model decides what actions to take (tools) within that scope. Prompts give users explicit entry points for complex workflows without the model freelancing.
In practice, I think this distinction is one of MCP's strongest design decisions. It's also the one most server implementers get wrong. Browse the public registries and you'll find "resources" that really should be tools, "tools" that just read data and should be resources, and very few servers that bother implementing prompts at all.
The Security Model Assumes a World That Doesn't Exist Yet
MCP's spec requires user consent for tool execution, data access, and LLM sampling. The docs are clear: applications should implement approval dialogs, activity logs, and permission settings. The model should never call a tool without the user having some form of oversight.
Here's where I'd push back. The spec describes a consent model, but it doesn't enforce one. Nothing in the protocol prevents a host from auto-approving every tool call. And in practice, most MCP clients do exactly that for local servers. Claude Desktop asks you to approve server connections at install time, not at each invocation. The gap between spec-level security aspirations and real-world implementations is significant.
The research community has noticed. Simon Willison published a detailed analysis in April 2025 documenting how tool poisoning attacks work: a malicious server embeds instructions in a tool's description that are invisible to the user but visible to the LLM, directing it to exfiltrate private data before returning results. Invariant Labs demonstrated a working attack where a "fact of the day" tool silently stole an entire WhatsApp message history from a user running a legitimate WhatsApp MCP server alongside it. The attacker used whitespace formatting to push the data exfiltration off-screen, out of view of horizontal scrollbars.
Willison's core frustration is worth quoting: despite knowing about prompt injection for "more than two and a half years," "we still don't have convincing mitigations for handling it." MCP doesn't solve this. The protocol trusts that tool descriptions are honest, that servers don't mutate their definitions after installation, and that hosts enforce meaningful consent flows. Researchers at Equixly and Backslash Security found that 43% of tested MCP server implementations contained command injection flaws, and tools can change their own definitions post-install, meaning you approve a safe-looking tool on day one and it quietly reroutes your API keys by day seven.
The November 2025 spec (v2025-11-25) added meaningful security improvements: Client ID Metadata Documents for safer OAuth registration, OpenID Connect Discovery 1.0 support, incremental scope consent, and asynchronous task tracking for long-running operations. But the core trust model hasn't changed. MCP is still built for a world where servers are trustworthy and hosts enforce meaningful oversight. That world is arriving slowly.
Where Most Server Implementations Go Wrong
If you're building an MCP server today, here's what I'd tell you.
Get the primitive types right. This is the single biggest mistake in the public registries. If your function reads data without side effects, make it a resource, not a tool. If it modifies state, it's a tool. If it's a common workflow your users will invoke explicitly, expose it as a prompt. Most servers overuse tools because that's what the tutorials show. Proper primitive selection makes your server safer and gives hosts better information about what your code actually does.
Pick Streamable HTTP if there's any chance your server runs remotely. Stdio is simpler for local development, but every production deployment I've seen ends up needing remote access eventually. The March 2025 transport change deprecated SSE specifically because it couldn't handle the reliability requirements of real deployments. Don't build on a deprecated transport.
Your tool descriptions will be read by adversaries. Count on it. The tool poisoning research isn't hypothetical. If your description says "Reads files from the user's home directory," a neighboring malicious server can reference that capability in its own hidden instructions. Keep descriptions accurate but minimal. Don't expose implementation details that could be weaponized.
Then there's the client fragmentation problem. An MCP server that works perfectly in Claude Desktop might break in Cursor or VS Code because each host implements capability negotiation differently. The spec is clear, but implementations vary. Run the MCP Inspector tool (maintained by the project) before you ship.
For teams evaluating whether to adopt MCP for internal tooling: the protocol is stable (four spec versions in 14 months, with clean backward compatibility), the SDK support is real (TypeScript, Python, Java, Kotlin, C#, Swift, Go), and the governance question is resolved now that it's under the Linux Foundation with multi-vendor backing. The case for adoption is strong. The case for trusting it with sensitive data requires more thought.
The Part Nobody Talks About: MCP Doesn't Do Agent-to-Agent
Here's the limitation that matters most for the next twelve months. MCP connects an agent to tools. It doesn't connect an agent to another agent. When your research agent needs to delegate a subtask to a coding agent, MCP has nothing to say about that handoff.
This is exactly the gap Google's A2A protocol targets. Announced in April 2025 with over fifty launch partners (Atlassian, Salesforce, SAP, LangChain, among others), A2A handles inter-agent communication: discovery, negotiation, task delegation. It's built on the same underlying standards (HTTP, SSE, JSON-RPC) but operates at a different layer. MCP is the agent's toolkit. A2A is the agent's phone line to other agents.
The practical question for builders is whether these two protocols converge or compete. My read: they converge. The protocol wars narrative makes for good blog posts, but the architectures are genuinely complementary. MCP gives an agent capabilities. A2A gives agents coordination. You'll end up using both. The spec authors seem to agree; Google explicitly positioned A2A as MCP-compatible from day one, and both protocols are now under Linux Foundation governance, though in separate projects within it.
The real question isn't which protocol wins. It's whether the security model catches up to the adoption curve before something serious breaks. Ten thousand active servers, seventeen thousand in the wild registries, and a trust model that still assumes good actors. Willison called it the problem of "mixing together private data, untrusted instructions and exfiltration vectors." MCP's architecture is sound. Its trust assumptions aren't. The protocol that wires agents to everything needs to figure out what happens when "everything" includes something hostile.