Grok 4.20 Just Shipped a 4-Agent Debate System. Here's Why It Matters.

Three days ago, xAI quietly shipped something no other consumer AI product has tried: a model that argues with itself before it talks to you. Grok 4.20, which entered public beta on February 17, doesn't just generate an answer. It spawns four specialized agents that research, verify, challenge, and synthesize in parallel, then hands you the consensus. The architecture builds on Grok 4.1's published hallucination improvement, from ~12% down to ~4.2%, a 65% reduction, with xAI claiming the multi-agent debate loop reduces errors further. Grok 4.20-specific data is pending formal benchmarks expected in mid-March. And in a live stock-trading competition, Grok 4.20 was the only AI model that made money.
This isn't a benchmark gimmick. It's a production architecture that points toward where all AI assistants are heading.
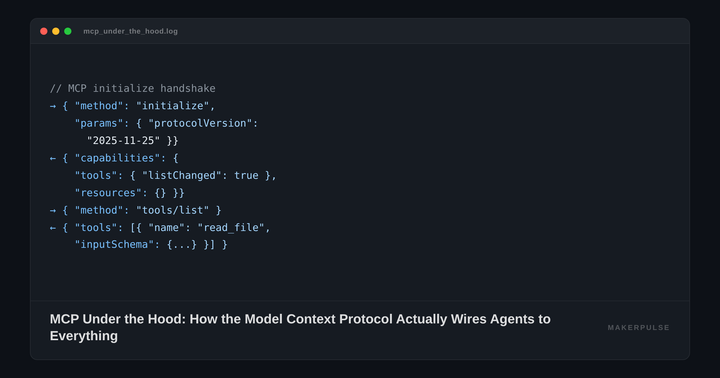
What Actually Happens When You Ask Grok a Question
Pick a hard prompt: "Should I use Rust or Go for a new microservices backend, given my team's Python background?" Here's the pipeline that fires inside Grok 4.20, according to xAI's published architecture details.
Phase 1: Decomposition. The Captain (Grok's coordinator agent) breaks the question into sub-tasks: language learning curves, runtime performance characteristics, hiring market realities, library maturity for microservices tooling.
Phase 2: Parallel analysis. Four agents attack these sub-tasks simultaneously:
- Grok/Captain handles task decomposition, strategy, conflict resolution, and final synthesis.
- Harper (research specialist) hits X's data firehose, processing roughly 68 million English posts per day, pulling real-time developer sentiment, recent migration reports, and current job listings.
- Benjamin (logic and code) runs step-by-step reasoning on performance benchmarks, type system comparisons, and compilation overhead. He stress-tests logical claims the other agents make.
- Lucas (creative/divergent thinker) looks for blind spots and biases. If the other three converge on "Rust is better," Lucas asks whether that conclusion holds for a team with zero systems programming experience and a six-month deadline.
Phase 3: Debate. This is the critical step that separates Grok 4.20 from a standard chain-of-thought model. The agents engage in structured internal rounds. If Benjamin's benchmarking conclusion contradicts Harper's real-world data, they challenge each other. Lucas flags when the group is anchoring on one perspective. The rounds are short, RL-optimized exchanges, not verbose multi-turn conversations.
Phase 4: Synthesis. The Captain aggregates results and produces a single coherent response with the disagreements resolved (or, when appropriate, flagged as genuinely unresolved).
The entire process runs concurrently on xAI's Colossus cluster (200,000+ GPUs). Because the agents share model weights and KV cache, the marginal compute cost is 1.5 to 2.5 times a single pass, not 4x. Simple queries don't trigger the full council; the system adapts based on complexity.
The Numbers So Far
Grok 4.20 is still in beta, with formal benchmarks promised after beta concludes around mid-March 2026. But there's already real-world evidence worth paying attention to.
Alpha Arena Season 1.5, a live stock-trading competition run by NoF1.ai, pits AI models against each other using real money on US stock tokens. Each model starts with $10,000 and trades for 14 days. Grok 4.20 (entered anonymously as a "Mystery Model") posted a +12.11% return, turning $10,000 into $12,193. It was the only model in the competition that finished in profit. GPT-5.1, Gemini 3.0 Pro, DeepSeek-3.1, and Kimi-2 all finished in the red.
Why did the multi-agent approach work for trading? Harper's real-time access to X's data stream let the system generate ultra-short-term sentiment signals within 1 to 5 minutes. Benjamin validated the quantitative logic. Lucas caught overconfidence in trending positions. The Captain decided when to act. It's an ideal use case for the architecture: high stakes, multiple data sources, and a strong penalty for hallucinating confidence.
On benchmarks, provisional LMArena Elo ratings put Grok 4.20 at 1505 to 1535, up from Grok 4.1's 1483. It ranked #2 globally on ForecastBench. The current beta runs a 500-billion parameter variant (the V8 foundation model), with medium and large versions still training. The full context window stretches to 2 million tokens in agentic modes, though standard queries use 256K.
The Bigger Pattern: Why This Matters Beyond Grok
Multi-agent debate isn't xAI's invention. The foundational research comes from a 2023 paper by Du, Li, Torralba, Tenenbaum, and Mordatch that showed multiple LLM instances proposing answers and debating across rounds could significantly reduce hallucinations and improve reasoning. A 2025 follow-up on adaptive heterogeneous multi-agent debate showed 4 to 6% higher accuracy and over 30% fewer factual errors compared to single-model approaches.
What xAI did was take this research pattern and bake it into the inference pipeline as a native, always-on feature. You don't orchestrate the agents. You don't write a framework. You ask a question, and the debate happens automatically.
This is likely the start of a much wider shift. Here's why:
The hallucination problem is the bottleneck for enterprise adoption. Every company evaluating AI tools for high-stakes work (legal research, financial analysis, medical literature review) hits the same wall: the model sounds confident but sometimes fabricates. Grok 4.1 already demonstrated a 65% hallucination reduction, and if the multi-agent debate loop pushes that number even lower under independent testing, the risk calculus shifts for these use cases.
The compute economics work. The naive assumption is that four agents cost four times as much. Grok 4.20's shared-weight, shared-KV-cache approach proves you can get multi-agent benefits at 1.5 to 2.5x cost. That's within the margin most enterprise customers would accept for a major accuracy improvement.
It doesn't require new models. The four agents in Grok 4.20 are specialized replicas of the same underlying model, not four different models. Any sufficiently large model could, in theory, adopt this pattern. Expect OpenAI, Google, and Anthropic to ship variants of this approach within 12 months. Moonshot AI already shipped one: Kimi K2.5's Agent Swarm spawns up to 100 parallel sub-agents trained via a new reinforcement learning method, delivering 4.5x speedups on parallel-friendly workloads.
What Practitioners Should Do Right Now
First, try it. Grok 4.20 is available to SuperGrok subscribers (~$30/month) and X Premium+ users through grok.com and the mobile apps. The four-agent mode activates automatically on complex queries. Test it on the kinds of questions where you've caught AI tools hallucinating before: multi-step research, quantitative analysis, questions that require synthesizing conflicting information.
Second, learn the pattern, not just the product. Multi-agent debate will become a standard feature across AI tools. Understanding it now, knowing that accuracy improvements come from structured disagreement rather than just larger models, will change how you evaluate every AI product launch for the next two years.
Third, watch for the benchmarks. xAI says formal results are coming after beta, around mid-March. The Alpha Arena performance is encouraging but narrow. The real question is whether the multi-agent debate loop delivers measurable hallucination gains across diverse domains (coding, scientific research, legal analysis) and not just trading.
The most important takeaway from Grok 4.20 isn't that xAI made a better chatbot. It's that the era of single-pass AI responses is ending. The next generation of AI tools won't just be bigger. They'll argue with themselves first, and they'll be better for it.