The First Model to Win Everything: GPT-5.3-Codex

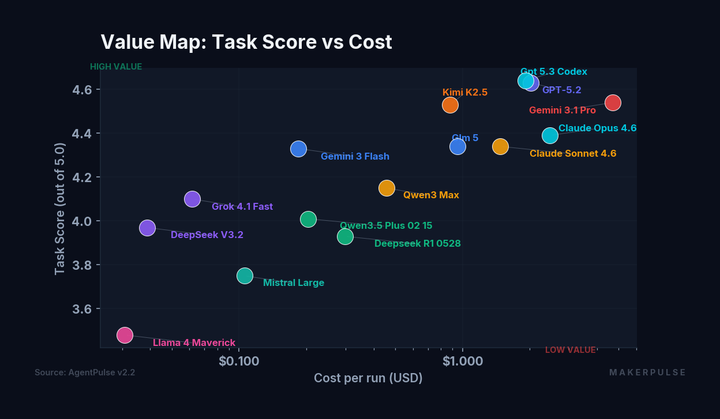
There's been a reliable tradeoff in frontier AI models for months: you pick the one that handles tasks well, or you pick the one that writes well. Not both. In the AgentPulse v2.2 benchmark, which tested 15 models across 28 prompts with three independent runs per model, GPT-5.2 led task quality at 4.63. Claude Sonnet 4.6 led creative writing at 4.01. Different models, different strengths. That's how it always worked.
GPT-5.3-Codex broke the pattern. It leads both.
What the numbers say
Codex scored 4.64 on task quality and 4.11 on creative writing. That makes it the first model in our benchmark to sit at the top of both leaderboards simultaneously.
But the leads aren't equal, and honesty about the data matters more than a clean headline.
The task improvement over GPT-5.2 is 0.01 points (4.64 vs 4.63). That's within the confidence interval (CI of 0.11 for Codex, 0.13 for GPT-5.2). You can't call that a meaningful gap. If we reran the benchmark tomorrow, GPT-5.2 might edge back ahead. The task lead is real in this dataset but not statistically decisive.
The creative improvement is the actual story. Codex scores 4.11, up from GPT-5.2's 3.87. That's a 0.24-point jump, or 6.2% improvement. It also edges past Claude Sonnet 4.6's previous creative lead of 4.01 by 0.10 points. That gap has CI overlap too (0.28 for Codex, 0.22 for Sonnet), so it's not a blowout. But the direction is clear: a coding-focused model released inside GitHub Copilot outscores Claude on creative writing. That was not on anyone's prediction list.
Where it dominates, where it doesn't
The track-level breakdown tells a more detailed story than the top-line numbers:
| Track | Codex | Leader | Gap |
|---|---|---|---|
| Professional | 4.69 | Codex | - |
| Reasoning | 4.72 | GPT-5.2 (4.75) | -0.03 |
| Comprehension | 4.59 | Qwen3-Max (4.64) | -0.05 |
| Everyday Writing | 4.55 | Opus 4.6 (4.57) | -0.02 |
| Constrained Creative | 4.64 | Gemini 3.1 Pro (4.70) | -0.06 |
Codex wins professional communication outright and never drops below 4.55 on any other track. It stays within 0.02-0.06 of the leader everywhere else. No other model in the benchmark achieves that consistency. Most models have at least one track where they drop significantly. Codex doesn't have a weak spot on the task side.
On the creative prompts, the standouts are striking. On the Shakespearean Sonnet prompt (P20), Codex scored 4.80 against GPT-5.2's 4.28, a 0.52-point gap and the largest creative-prompt improvement over its predecessor. On Science Fiction (P23), Codex hit 4.22, leading every model including Opus (4.00) and Sonnet (3.94).
The weak spots are just as real. On Micro-Fiction (P28), Codex scored 3.46, good enough for 4th among the top five models, behind Sonnet (3.62), GPT-5.2 (3.60), and Opus (3.56). Compression forces default patterns, and Codex falls into them more than its competitors. Perspective Shift (P19) shows a similar gap: Codex at 4.38 while Sonnet scores 4.65.
Cheaper and faster than its predecessor
Here's what makes the Codex result practical, not just interesting on a benchmark chart: it's cheaper and faster than the model it replaced.
| GPT-5.3-Codex | GPT-5.2 | |
|---|---|---|
| Task Score | 4.64 | 4.63 |
| Creative Score | 4.11 | 3.87 |
| Total Cost (28 prompts) | $1.92 | $2.03 |
| Avg Latency | 35.9s | 56.9s |
That's 5.4% cheaper and 37% faster while matching or exceeding GPT-5.2 on every quality metric. For builders running these models at scale, the cost and speed improvements compound fast. You're getting more for less.
For context: Claude Sonnet 4.6 remains the cost-efficiency leader at $1.48 for competitive quality (task 4.34, creative 4.01). Gemini 3.1 Pro, despite strong track scores, costs $4.69, nearly 2.5x what Codex charges for lower overall scores. The full benchmark breakdown has the complete cost-quality comparison across all 15 models.
What benchmarks miss
In my own work, I still reach for Opus.
That's not a contradiction of the data. The AgentPulse benchmark tests models on isolated, single-turn prompts: write this email, plan this trip, draft this story. On those tasks, the data is clear. Codex wins. But my daily workflow is multi-step, multi-agent coordination: an orchestration layer that spawns sub-agents, manages file system state, chains complex decisions across long contexts. That's a fundamentally different challenge, and it's one that single-task benchmarks can't capture.
This isn't a knock on the methodology. It's an honest observation about the limits of what any benchmark measures. The model that scores highest on 28 individual prompts may not be the model that handles a 50-step pipeline most reliably. Both pieces of information matter.
What this means for builders
If you're choosing a model for practical tasks like emails, documents, analysis, and professional writing, Codex is the new default recommendation from our data. It leads on task quality, leads on creative quality, and does both at lower cost and latency than GPT-5.2.
If you're building systems that chain multiple model calls together, the answer is less clear. Single-task quality is necessary but not sufficient. Reliability, instruction-following over long contexts, and consistency across dozens of sequential calls all matter, and none of them show up in a 28-prompt benchmark.
The familiar builder tradeoff between task quality and creative quality just got smaller. Whether it's actually gone depends on whether your workload looks like our benchmark or like something more complex.
All data from AgentPulse v2.2. 15 models, 28 prompts, 3 runs per model, median aggregation, triple-evaluator panel. Full methodology and raw data available at data.makerpulse.ai.