AgentPulse: The Independent AI Benchmark
Last updated: February 2026 | AgentPulse v2.2 | 15 models, 28 prompts, 1,260 evaluations
We built AgentPulse because we needed data nobody was publishing.
Every model provider has a benchmarks page. Every benchmarks page tells the same story: their model is great. The tests are usually coding puzzles and academic trivia. Useful if you're choosing a model for code generation, less useful if you're trying to figure out which model writes the best customer emails, catches details in a messy meeting transcript, or produces fiction that doesn't read like it was assembled from a template.
AgentPulse, the research wing of MakerPulse, tests what practitioners actually do with language models outside of code editors. We run 28 prompts across five tracks (everyday writing, comprehension, reasoning, professional tasks, and constrained creative writing), then score the outputs with a three-evaluator panel, three independent runs per model, median scores reported. The methodology is open-source. The raw data is free. We update the results every time the playing field shifts.
Here's what we found across 15 frontier models.
The Rankings
Task Performance
Task score measures how well a model handles practical, non-coding work: drafting emails, extracting information from documents, reasoning through problems, producing professional deliverables.
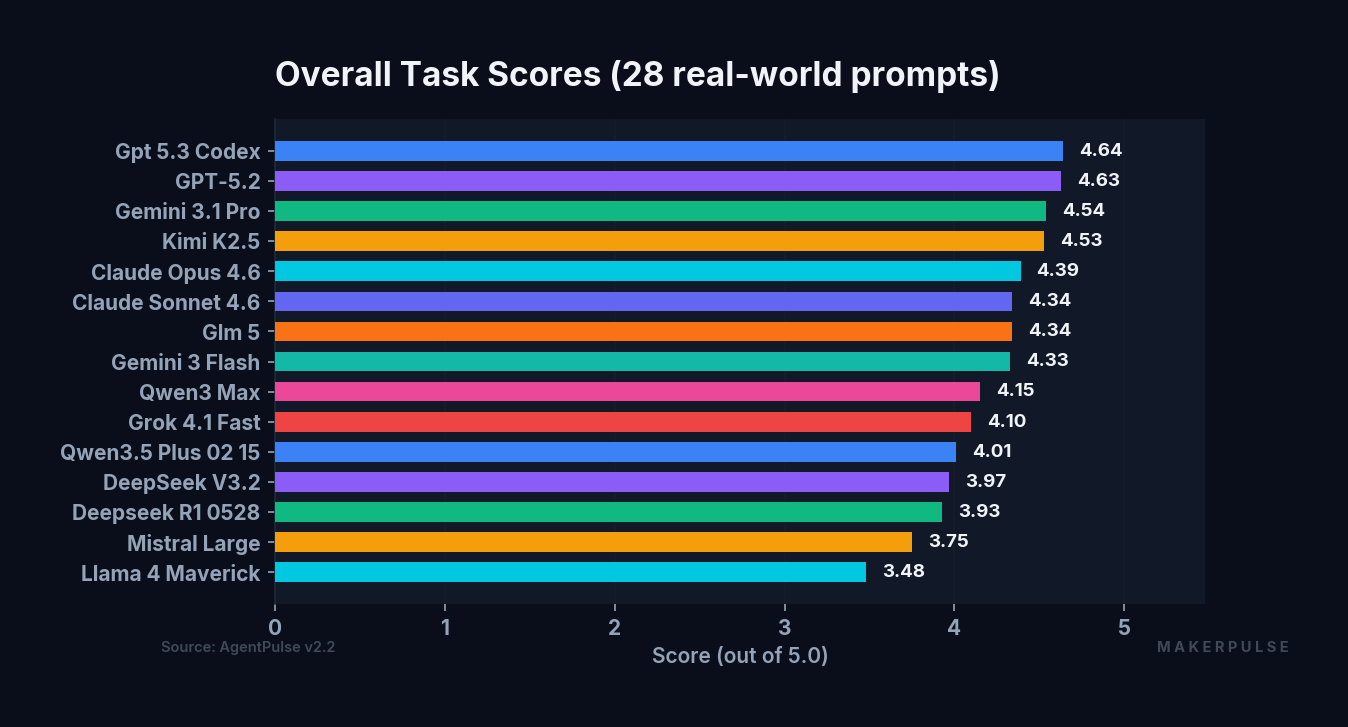
The full task ranking:
| Rank | Model | Task Score |
|---|---|---|
| 1 | GPT-5.3 Codex | 4.64 |
| 2 | GPT-5.2 | 4.63 |
| 3 | Gemini 3.1 Pro | 4.54 |
| 4 | Kimi K2.5 | 4.53 |
| 5 | Claude Opus 4.6 | 4.39 |
| 6 | Claude Sonnet 4.6 | 4.34 |
| 7 | GLM 5 | 4.34 |
| 8 | Gemini 3 Flash | 4.33 |
| 9 | Qwen3 Max | 4.15 |
| 10 | Grok 4.1 Fast | 4.10 |
| 11 | Qwen3.5 Plus | 4.01 |
| 12 | DeepSeek V3.2 | 3.97 |
| 13 | DeepSeek R1 | 3.93 |
| 14 | Mistral Large | 3.75 |
| 15 | Llama 4 Maverick | 3.48 |
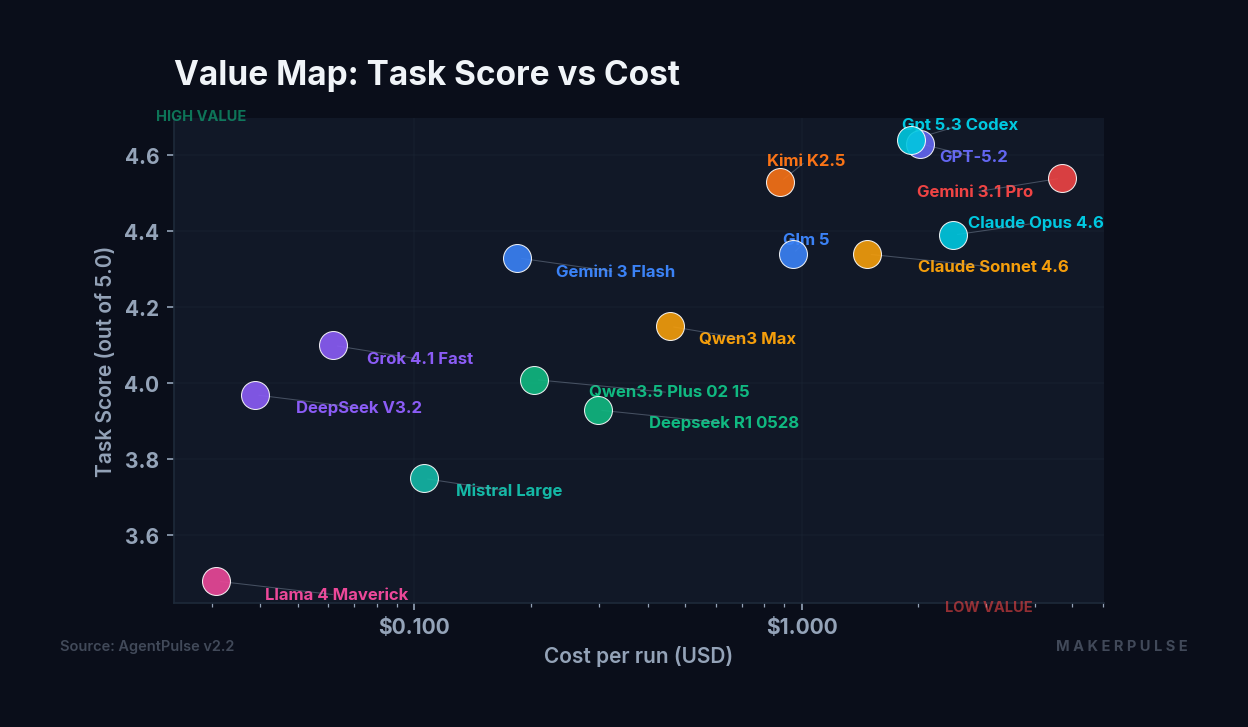
The task score spread from bottom to top is 1.16 points. That's relatively compressed. Most frontier models handle practical tasks competently. The difference between 8th and 3rd place is 0.21 points. If all you need is solid everyday text work, you have a lot of good options.
The real separation happens elsewhere.
Creative Writing
Creative score measures constrained fiction: psychological horror, unreliable narrators, comedy, micro-fiction, character-driven scenes. We evaluate on prose craft, imagination and risk-taking, character and dialogue, emotional architecture, and AI tell absence (a checklist-based deduction for patterns that flag text as machine-generated).
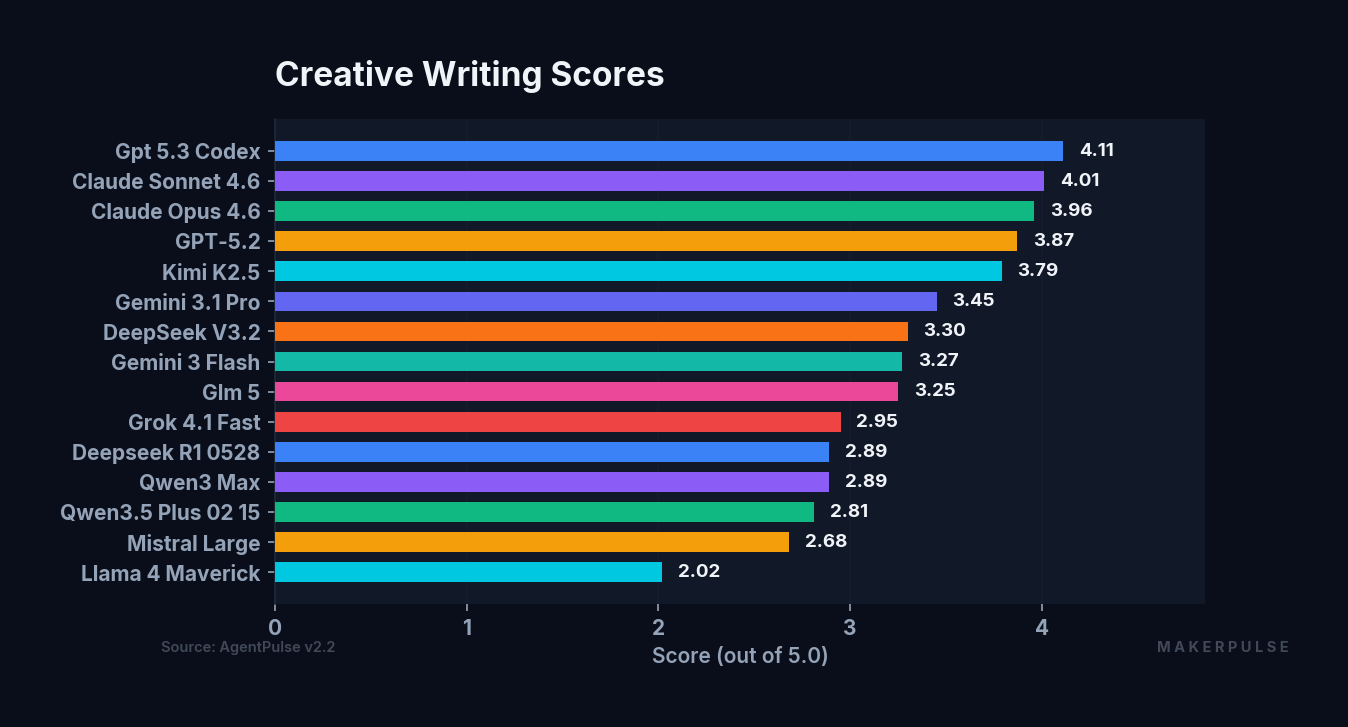
| Rank | Model | Creative Score |
|---|---|---|
| 1 | GPT-5.3 Codex | 4.11 |
| 2 | Claude Sonnet 4.6 | 4.01 |
| 3 | Claude Opus 4.6 | 3.96 |
| 4 | GPT-5.2 | 3.87 |
| 5 | Kimi K2.5 | 3.79 |
| 6 | Gemini 3.1 Pro | 3.45 |
| 7 | DeepSeek V3.2 | 3.30 |
| 8 | Gemini 3 Flash | 3.27 |
| 9 | GLM 5 | 3.25 |
| 10 | Grok 4.1 Fast | 2.95 |
| 11 | DeepSeek R1 | 2.89 |
| 12 | Qwen3 Max | 2.89 |
| 13 | Qwen3.5 Plus | 2.81 |
| 14 | Mistral Large | 2.68 |
| 15 | Llama 4 Maverick | 2.02 |
The creative spread is 2.09 points, nearly double the task spread. Models that look similar on everyday tasks diverge dramatically when you ask them to write fiction. Gemini 3.1 Pro places 3rd in task performance but drops to 6th in creative. GLM 5 ties for 6th on tasks but falls to 9th in creative. The creative track separates models that can follow instructions from models that can write.
This tracks with what we'd expect. Creative writing is hard from multiple angles simultaneously: structure, voice, emotional arc, character consistency, pacing, the ability to resist tidy resolutions and AI-flavored prose. A model can score well on task work by being accurate and clear. Scoring well on creative work requires something closer to taste. We think creative and long-form writing will be the last capability AI fully masters, and the spread in the data reflects how far most models still have to go.
The Surprises
A Coding Model Leads Creative Writing
GPT-5.3 Codex tops both the task ranking (4.64) and the creative ranking (4.11). That second number is the surprise. Codex is OpenAI's coding-optimized model, built for structured, logical output. And it writes the best fiction in our benchmark.
The gap is meaningful. Codex leads the second-place creative model (Claude Sonnet 4.6 at 4.01) by 0.10 points. It produces prose with fewer AI tells, takes more structural risks, and handles character voice with more consistency than any other model we tested.
We don't have a clean explanation for why a coding model excels at creative writing. One theory: the kind of structured reasoning that makes a model good at code (tracking state across a long context, maintaining consistency, planning ahead) might also help with fiction. Characters are state. Plot is control flow. But that's speculation. The data says what it says.
The more interesting question: if the coding variant is this good, what will the standard GPT-5.3 look like when it releases?
Claude Sonnet Beats Opus on Creative, Not Task
Claude Sonnet 4.6 scores 4.01 on creative writing. Claude Opus 4.6 scores 3.96. The smaller, cheaper model edges the flagship on prose quality.
But flip to task performance and the order reverses: Opus scores 4.39, Sonnet scores 4.34. Opus wins on practical work.
This is a useful result for practitioners. If you're routing model calls and your task involves writing prose (marketing copy, narrative content, anything where voice and craft matter), Sonnet is the better pick from the Claude family. For complex analytical or professional tasks, Opus pulls ahead.
There's something this benchmark doesn't capture, though. I use Opus daily for extended multi-step work in Claude Code: coordinating multiple agents, managing long-horizon planning, making judgment calls across dozens of files. Single-prompt benchmarks can't measure that kind of sustained orchestration. The model that's best at answering one question well isn't necessarily the model that's best at managing a complex project across hundreds of turns. That's an area AgentPulse plans to investigate in future benchmark expansions.
The Cost Map
Cost varies by more than 150x across the models we tested.
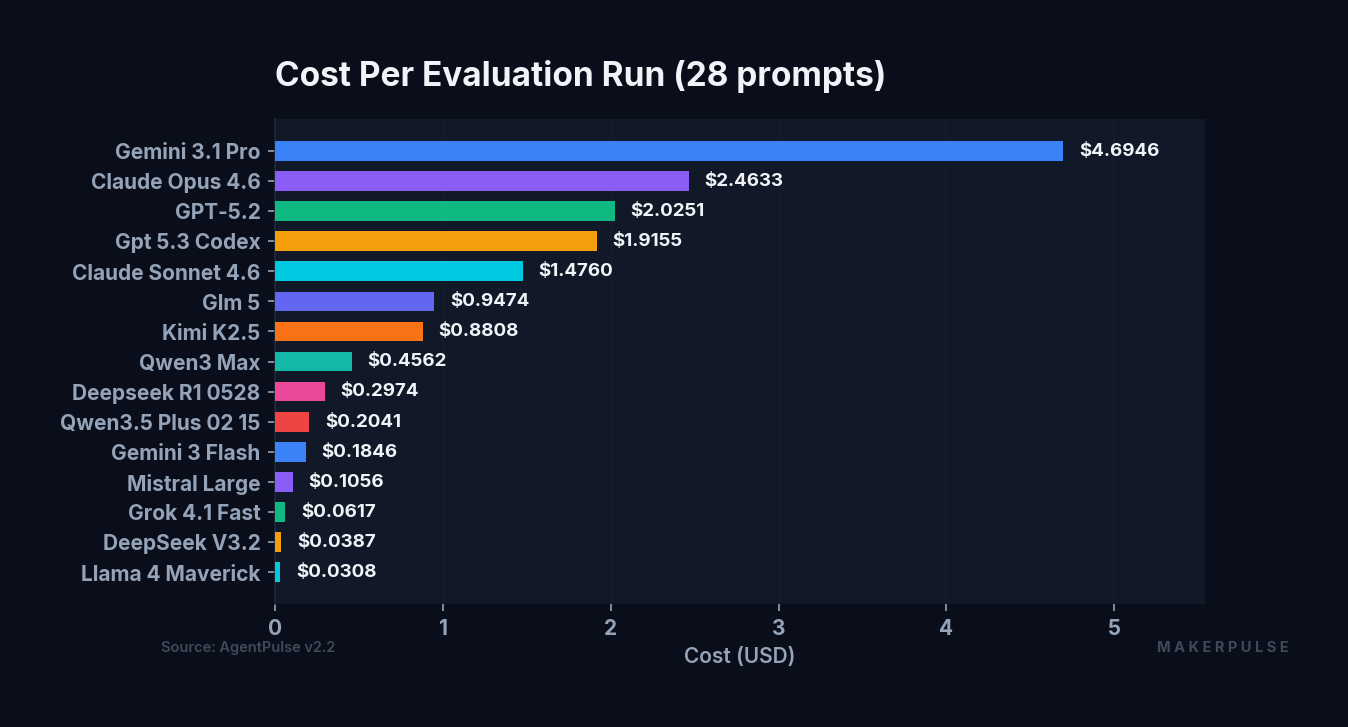
| Model | Cost (28 prompts) | Task Score |
|---|---|---|
| Llama 4 Maverick | $0.0308 | 3.48 |
| DeepSeek V3.2 | $0.0387 | 3.97 |
| Grok 4.1 Fast | $0.0617 | 4.10 |
| Mistral Large | $0.1056 | 3.75 |
| Gemini 3 Flash | $0.1846 | 4.33 |
| Qwen3.5 Plus | $0.2041 | 4.01 |
| DeepSeek R1 | $0.2974 | 3.93 |
| Qwen3 Max | $0.4562 | 4.15 |
| Kimi K2.5 | $0.8808 | 4.53 |
| GLM 5 | $0.9474 | 4.34 |
| Claude Sonnet 4.6 | $1.4760 | 4.34 |
| GPT-5.3 Codex | $1.9155 | 4.64 |
| GPT-5.2 | $2.0251 | 4.63 |
| Claude Opus 4.6 | $2.4633 | 4.39 |
| Gemini 3.1 Pro | $4.6946 | 4.54 |
The cheapest option (Llama 4 Maverick at $0.0308) isn't just cheap. It's two orders of magnitude less than the most expensive (Gemini 3.1 Pro at $4.6946). But Maverick also places last in both task and creative scores. You get what you pay for, to a point.
The value standouts are in the middle. Kimi K2.5 costs $0.88 and places 4th in task (4.53) and 5th in creative (3.79), competitive with models costing twice as much. DeepSeek V3.2 is the budget pick at $0.0387, delivering a 3.97 task score that beats models costing three to ten times more. Gemini 3 Flash at $0.1846 scores 4.33 on tasks, punching well above its price point.
At the top end, spending more doesn't guarantee proportionally better results. Gemini 3.1 Pro costs $4.69 (nearly double Claude Opus at $2.46) and scores 4.54 on tasks versus Opus's 4.39. That's a 0.15-point improvement for a 91% price premium. Whether that tradeoff makes sense depends entirely on your use case and volume.
Hallucinations
We track factual hallucinations across all 28 prompts. A hallucination is scored when a model fabricates specific facts, cites sources that don't exist, or makes claims that contradict the information provided in the prompt.
Rather than report hallucination rates as percentages, we use raw counts. On a 28-prompt test, the difference between "4% hallucination rate" and "7% hallucination rate" is one prompt. Percentages make the differences sound larger than they are.
Lowest hallucination counts: - GPT-5.2: 1 of 28 prompts - GPT-5.3 Codex: 1 of 28 prompts - GLM 5: 2 of 28 prompts - Llama 4 Maverick: 3 of 28 prompts
Mid-range: - DeepSeek R1: 5 of 28 - Gemini 3.1 Pro: 5 of 28 - Gemini 3 Flash: 6 of 28 - DeepSeek V3.2: 7 of 28 - Grok 4.1 Fast: 7 of 28
Highest hallucination counts: - Claude Opus 4.6: 8 of 28 - Kimi K2.5: 8 of 28 - Qwen3 Max: 8 of 28 - Claude Sonnet 4.6: 9 of 28 - Qwen3.5 Plus: 9 of 28 - Mistral Large: 12 of 28
Two things stand out. First, the OpenAI models are notably clean. Both GPT-5.2 and GPT-5.3 Codex hallucinated on only 1 of 28 prompts. Second, hallucination count and overall quality don't correlate the way you might expect. Claude Sonnet 4.6 has one of the higher hallucination counts (9 of 28) but places 2nd in creative writing and 6th in task performance. Mistral Large hallucinated on 12 of 28 prompts (nearly half), which is a significant reliability concern regardless of its other scores.
Methodology
AgentPulse v2.2 uses 28 prompts across five tracks:
- Everyday Writing (emails, messages, personal correspondence)
- Comprehension (extracting information from messy, realistic source material)
- Reasoning (multi-step problems requiring inference and judgment)
- Professional (business documents, reports, deliverables)
- Creative Constrained (fiction with specific structural requirements)
Each model runs every prompt three times. We report the median score to reduce variance from single-run noise.
A three-evaluator panel scores every response: Claude Opus 4.6, Gemini 3.1 Pro, and GPT-5.2. Using evaluators from different providers reduces the risk of systematic bias from any single model family. Inter-rater reliability sits at a Pearson r of 0.71 with a mean absolute difference of 0.565, showing adequate agreement with healthy evaluator independence.
Creative writing uses a separate rubric with a checklist-based AI tell scoring system. Evaluators start at 5.0 and deduct 0.5 for each category of detected AI writing pattern (structural tells, lexical tells, voice tells, creative tells, character name patterns, dialogue tells). This makes the most subjective dimension more objective and reproducible.
All prompts, rubrics, raw evaluation data, and methodology documentation are published at data.makerpulse.ai. We built this to be auditable. If our methodology has a flaw, we want to know about it.
How to Use This Data
Benchmarks are decision-support tools, not oracles. Here's how we'd suggest reading these results:
If you need a general-purpose text model and cost isn't a constraint: GPT-5.3 Codex leads both task and creative rankings. GPT-5.2 is a fraction behind on tasks at a comparable price point, though it drops to 4th on creative (3.87 vs Codex's 4.11).
If you need strong creative writing: GPT-5.3 Codex (4.11), Claude Sonnet 4.6 (4.01), and Claude Opus 4.6 (3.96) are the top tier. The drop to 4th place (GPT-5.2 at 3.87) is noticeable.
If you're optimizing for cost: DeepSeek V3.2 delivers a 3.97 task score at $0.0387, and it's hard to beat on value. Gemini 3 Flash at $0.1846 gets you into the 4.33 task score range. Kimi K2.5 at $0.88 reaches the top tier on tasks (4.53).
If hallucination risk is your primary concern: GPT-5.2 and GPT-5.3 Codex each hallucinated on only 1 of 28 prompts. GLM 5 at 2 of 28 is also strong.
If you need speed: Gemini 3 Flash averages 6,621ms per response. Llama 4 Maverick averages 5,221ms. At the other end, Kimi K2.5 averages 107,384ms, nearly two minutes per response.
What This Benchmark Doesn't Measure
Transparency matters more than marketing. Here's what AgentPulse v2.2 can't tell you:
Multi-turn conversation. Every prompt is a single turn. Models that excel at maintaining context across long conversations may not show that advantage here.
Coding ability. AgentPulse focuses exclusively on non-coding text tasks. For code benchmarks, look at SWE-bench, HumanEval, or the providers' own code evaluations.
Agent orchestration. How a model performs as the backbone of a multi-agent system (maintaining state, coordinating subtasks, making judgment calls over extended workflows) is a fundamentally different capability than single-prompt response quality. This is the gap we feel most acutely as practitioners. It's also the hardest thing to benchmark rigorously, and it's on the AgentPulse roadmap.
Long-form writing. Our creative prompts max out at 1,500 words. Novel-length consistency, pacing across chapters, and the ability to maintain voice over tens of thousands of words are untested.
Subjective preference alignment. Two models can score identically and still feel different to use. Personal preference for a model's default tone, verbosity level, or interaction style isn't something a rubric captures.
We update this benchmark when the model lineup changes materially: new model releases, significant version updates, or methodology improvements. The goal isn't a daily leaderboard. It's a reliable reference for practitioners making real decisions about which models to use and how much to spend.
AgentPulse is the research arm of MakerPulse. Full methodology, raw evaluation data, and machine-readable results are available at data.makerpulse.ai. The benchmark is updated regularly as new frontier models are released.


